MindBench: A Comprehensive Benchmark for Mind Map Structure Recognition and Analysis
Abstract
Multimodal Large Language Models (MLLM) have made significant progress in the field of document analysis. Despite this, existing benchmarks typically focus only on extracting text and simple layout information, neglecting the complex interactions between elements in structured documents such as mind maps and flowcharts. To address this issue, we introduce the new benchmark named MindBench, which not only includes meticulously constructed bilingual authentic or synthetic images, detailed annotations, evaluation metrics and baseline models, but also specifically designs five types of structured understanding and parsing tasks. These tasks include full parsing, partial parsing, position-related parsing, structured Visual Question Answering (VQA), and position-related VQA, covering key areas such as text recognition, spatial awareness, relationship discernment, and structured parsing. Extensive experimental results demonstrate the substantial potential and significant room for improvement in current models' ability to handle structured document information. We anticipate that the launch of MindBench will significantly advance research and application development in structured document analysis technology.
The pipeline of the MindBench benchmark
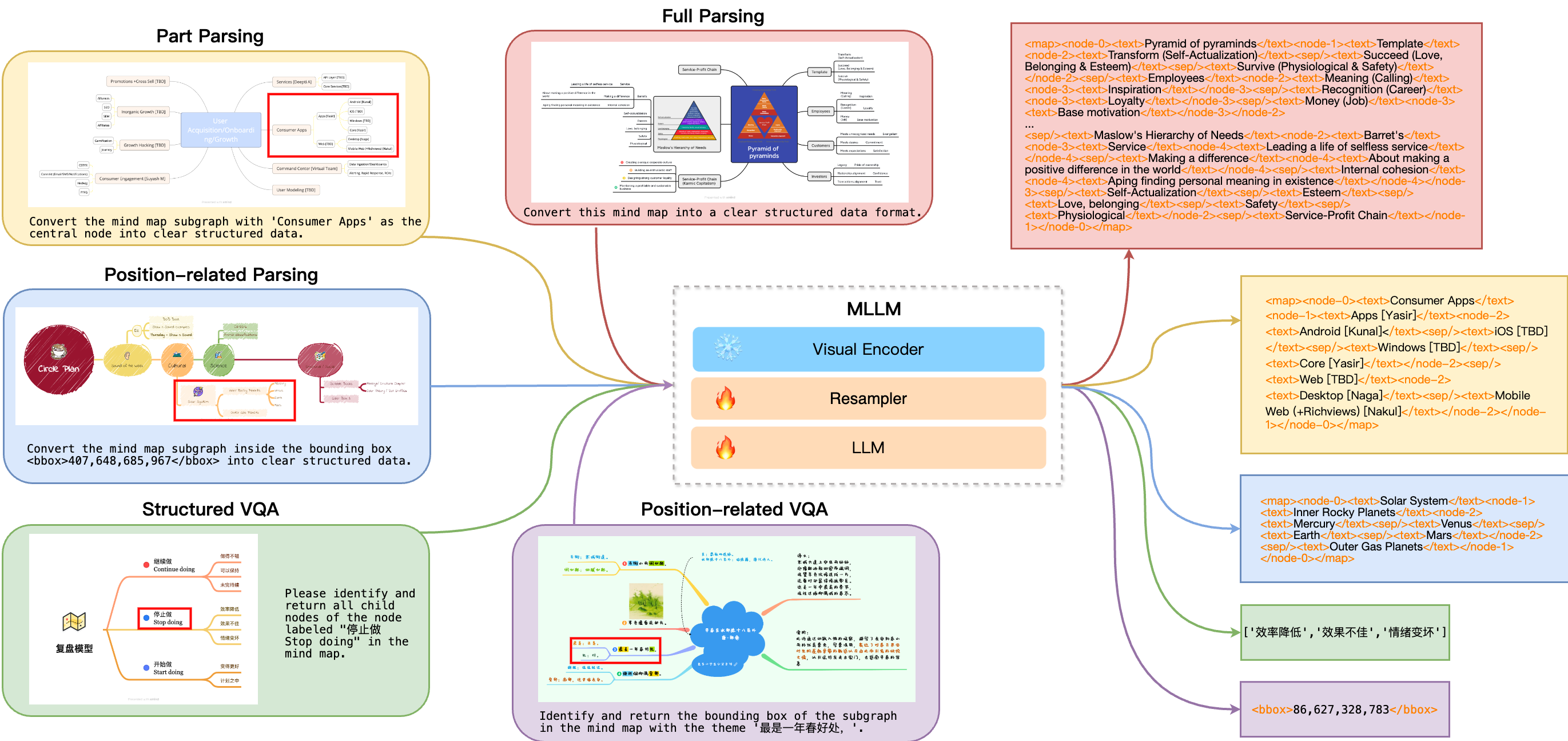
We design five structured understanding and parsing tasks, as illustrated in Figure, including full parsing, partial parsing, position-related parsing, structured VQA, and position-related VQA.
Full parsing requires the model to return the full parsing results of the input mind map image. Mind map images often have significantly higher resolutions than typical document images, with some exceeding 10,000 pixels. This demands models capable of processing high-resolution images. Furthermore, higher resolution mind maps contain more information, resulting in longer structured data, which presents a significant challenge for existing models.
Part parsing involves returning a subgraph centered around a specific node, resulting in shorter token output. However, it also poses new challenges, requiring the model to accurately identify the central theme node from the question and return its corresponding subgraph.
Position-related parsing also returns a subgraph of the mind map. The difference is that this task emphasizes spatial positioning, requiring the model to integrate capabilities in text recognition, spatial awareness, and relational parsing.
Structured VQA is designed to explicit learning of the components of mind maps and their interrelationships. We design multiple VQA tasks related to node kinship and hierarchical relationships.
Position-related VQA is divided into two categories: recognition and grounding. In recognition tasks, the model receives node coordinates and returns answers about structural information. In grounding tasks, the model receives node descriptions and returns the bounding box coordinates of the corresponding structure.
These tasks comprehensively assess the models' abilities to parse text and image information, recognize relationships between elements, and understand the overall structure.
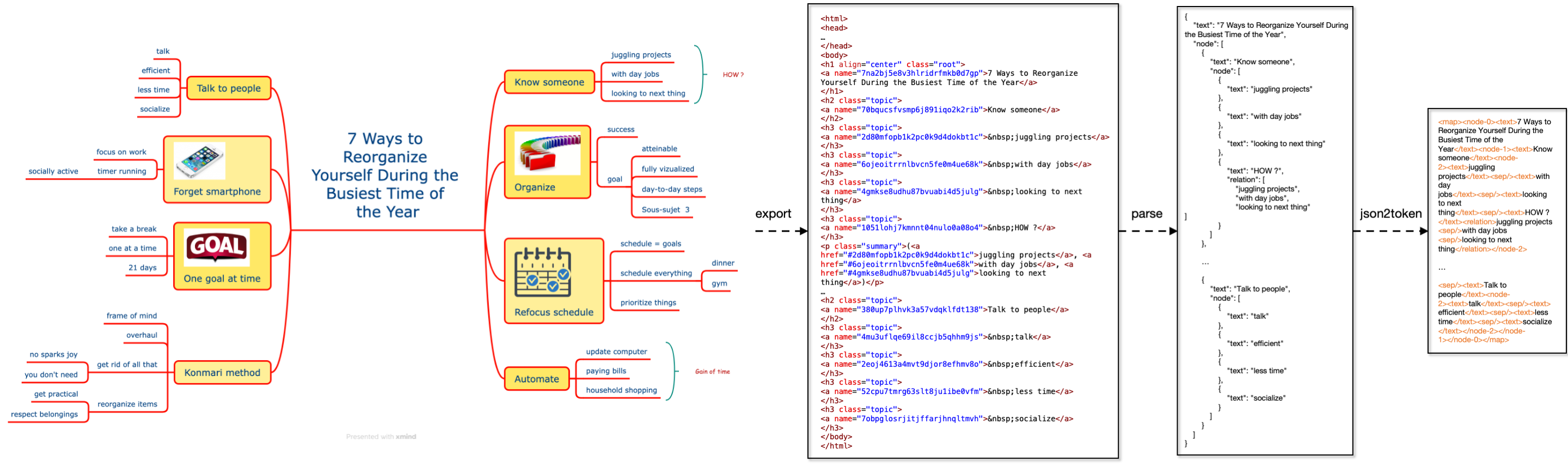
The illustration of data parsing
Statistic


Experiments
Comparison with SOTA MLLMs
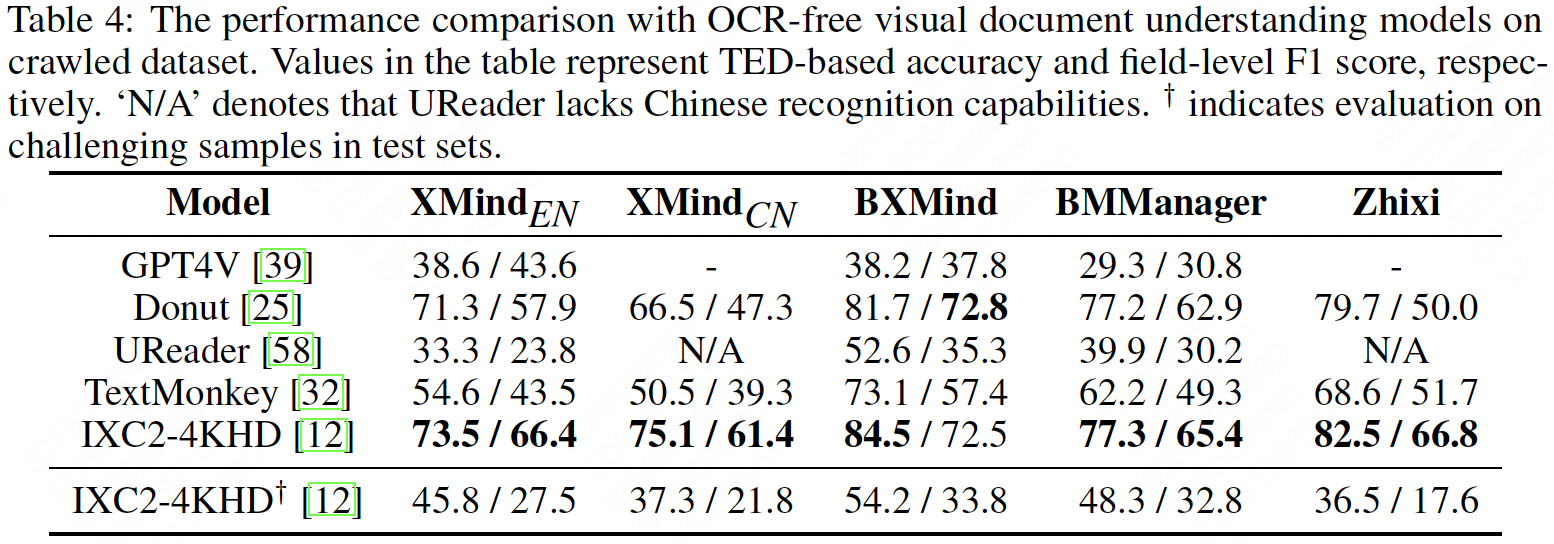
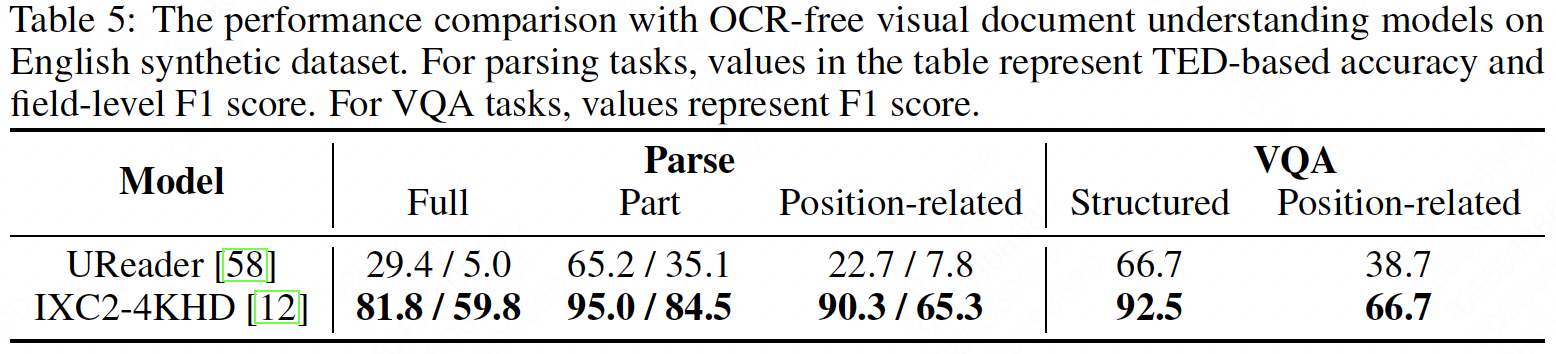
We compare the performance of visual document understanding models on the MindBench benchmark. GPT4V shows mediocre performance, indicating challenges for commercial models in parsing complex structured documents like mind maps. Donut ranks second, outperforming UReader and TextMonkey, approaching the performance of IXC2-4KHD. IXC2-4KHD achieves the best performance due to extensive OCR data pre-training and higher resolution input. However, MLLMs still have limitations in analyzing complex mind maps. Additionally, position-related tasks pose challenges in integrating structured understanding with spatial perception.
Ablation Study
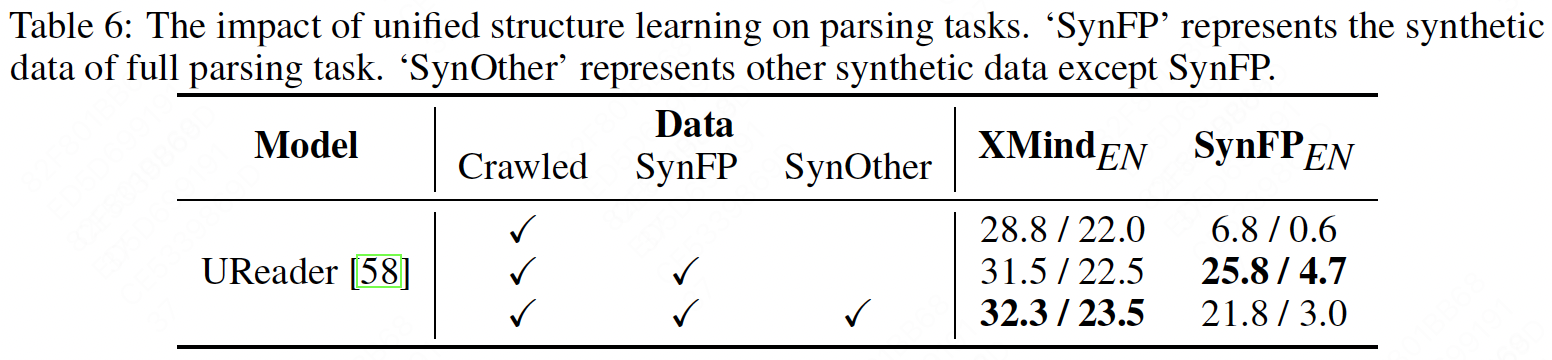
We conduct ablation experiments to analyze the impact of unified structure learning. The results show that incorporating synthetic data significantly improves the parsing performance on real mind maps. Additionally, unified structure learning effectively captures inter-node relationships and spatial information, further enhancing the accuracy of parsing.
BibTeX
@article{chen2024mindbench,
title={MindBench: A Comprehensive Benchmark for Mind Map Structure Recognition and Analysis},
author={Chen, Lei and Yan, Feng and Zhong, Yujie and Chen, Shaoxiang and Jie, Zequn and Ma, Lin},
journal={arXiv preprint arXiv:2407.02842},
year={2024}
}